Recommended
How can QA engineers leverage application logs

As a software application scales or starts to experience more traffic, higher-volume logs often emerge as a result.
This surge in logs can be overwhelming, making it challenging to pinpoint issues or get insights for improving the app.
To navigate this sea of information, you need a structured approach and the right tools. This article dives deep into five best practices for managing logs, ensuring you can extract value without drowning in data.
By implementing these strategies, you’ll be better equipped to address the challenges posed by high-volume logs, ensuring smooth operations and more efficient debugging.
Let’s start by understanding the importance of log levels.
Table of Contents
Organization is a fundamental aspect of managing app logs effectively, and at the heart of it lies the concept of standardized log levels.
Every app, regardless of its complexity, generates a vast amount of information. This information covers all aspects of the app and its functionality, along with the many user actions taken within it.
However, without a systematic way to categorize this data based on its type and significance, developers and other stakeholders can easily find themselves overwhelmed while trying to make sense of it all.
That’s where standardization comes in.

The image above illustrates the six most frequently used log levels, arranged by urgency, starting from trace logs to fatal-level ones. Each log level conveys a specific type of information and informs you of what is the appropriate action to be taken.
For instance, consider a transaction processing app. If there was an error in the final step of the transaction, it would be categorized as fatal.

Get unreal data to fix real issues in your app & web.
On the other hand, a lesser hiccup, like an issue displaying a customer’s zip code, might fall under error or perhaps the warn level.
Logs below the warn level typically offer valuable information or debugging data. This data, while not immediately pressing, is invaluable for developers aiming to optimize performance or address bugs.
For a more in-depth look into log levels, check out our article on the topic.
In any case, once you standardize the levels, high-volume logs start to become more manageable.
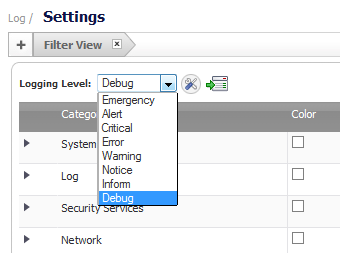
As depicted above, many log-tracking tools facilitate this process by allowing you to filter data by log levels.
Searching for fatal-level logs that demand immediate attention?
If your logs are neatly organized, a few clicks are all it takes to pinpoint them. This efficiency is crucial, especially when time is of the essence in addressing app-breaking issues.
In conclusion, a structured approach can help you manage high-volume app logs more efficiently, and adopting standardized log levels is an essential step.
While understanding and implementing log levels is a step in the right direction, consistency in logging practices is equally crucial.
This consistency ensures that the log levels are not just there in theory but used in a practical way to genuinely aid in managing app logs.
Consistency in logging offers two primary advantages—it reduces ambiguity and makes logs more straightforward to analyze.
When logs are consistent, there’s no second-guessing or unnecessary backtracking to understand what each entry signifies.
After all, if your team agrees on what a fatal-level log is, you shouldn’t find a minor issue logged there. In the same line, something logged as info wouldn’t have a bug or critical error there.
First things first, you need to define what each log level contains.

The image above shows an answer in a StackOverflow discussion where a user sought clarity on what to log under which level.
The response gave a rough guideline for some logging levels, which are a great starting point.
The next image further breaks down each of the six log levels and the kind of information typically associated with each of them.
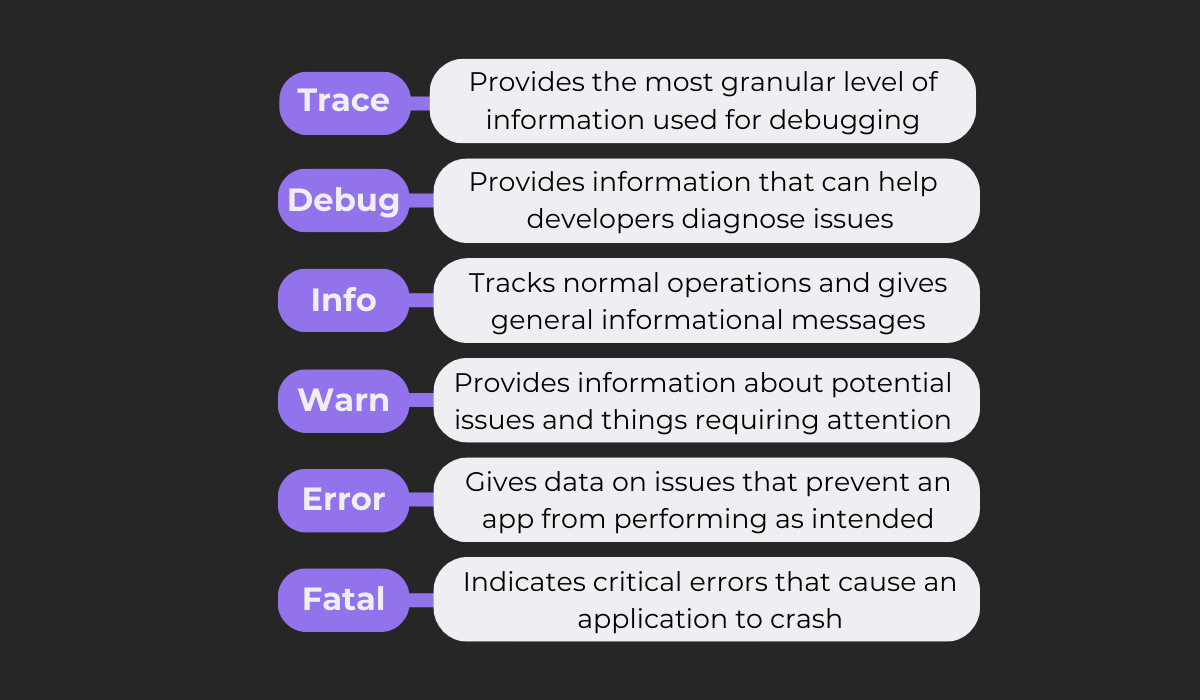
While teams have the flexibility to tweak these definitions to suit their specific needs, maintaining consistency is non-negotiable.
As one final point, we must stress that consistency isn’t just about labeling information at an appropriate log level but ensuring that each log entry is comprehensive and informative—constantly adding relevant context to logs.
The image above contrasts two logs.
While both might be labeled as warnings, the first is vague, leaving developers in the dark as to what record wasn’t found.
In contrast, the second log is detailed, allowing for a more swift and effective resolution.
Overall, the shared understanding gained by logging consistently and comprehensively ensures that everyone, from junior developers to senior architects, is on the same page.
Now that we’ve covered the what and how of logging, let’s take a look at the why.
Every log entry should serve a specific purpose, whether to inform about routine app operations, warn developers about potential issues, or alert them about app crashes and critical failures.
Logs shouldn’t be generated arbitrarily or without clear intent.
The quote from Coralogix illustrated next showcases an important way of thinking about logging.
Instead of indiscriminately logging every minute detail, it’s more efficient to log with intention.
Ask yourself, what questions do I need answered about my app? What insights am I trying to gain?
For instance, if you’re keen on understanding the efficiency of your app’s payment functionalities, flooding your logs with data from the accelerometer and tracking a device’s movement might not be the best approach.
However, that same data could be invaluable if you’re developing a motion-based game.
Once you figure out what information you need about your app, there are various types of logs to help you answer these questions.
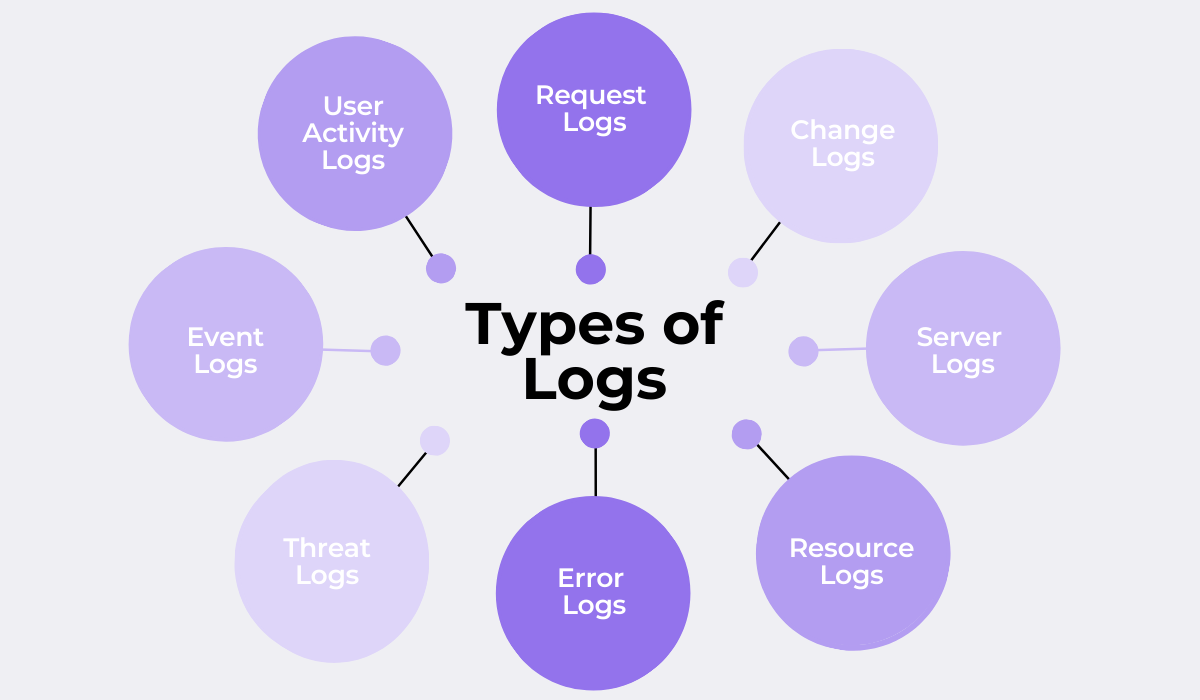
Broadly speaking, these various logs should provide insights into your app’s functionalities, performance, reliability, and security.
These insights help in identifying bottlenecks, ensuring smooth user experiences, and maintaining robust security protocols.
Moreover, let’s not forget that different logs serve varied purposes for various team members.
The image below shows what logging enables some teams in an organization to achieve.
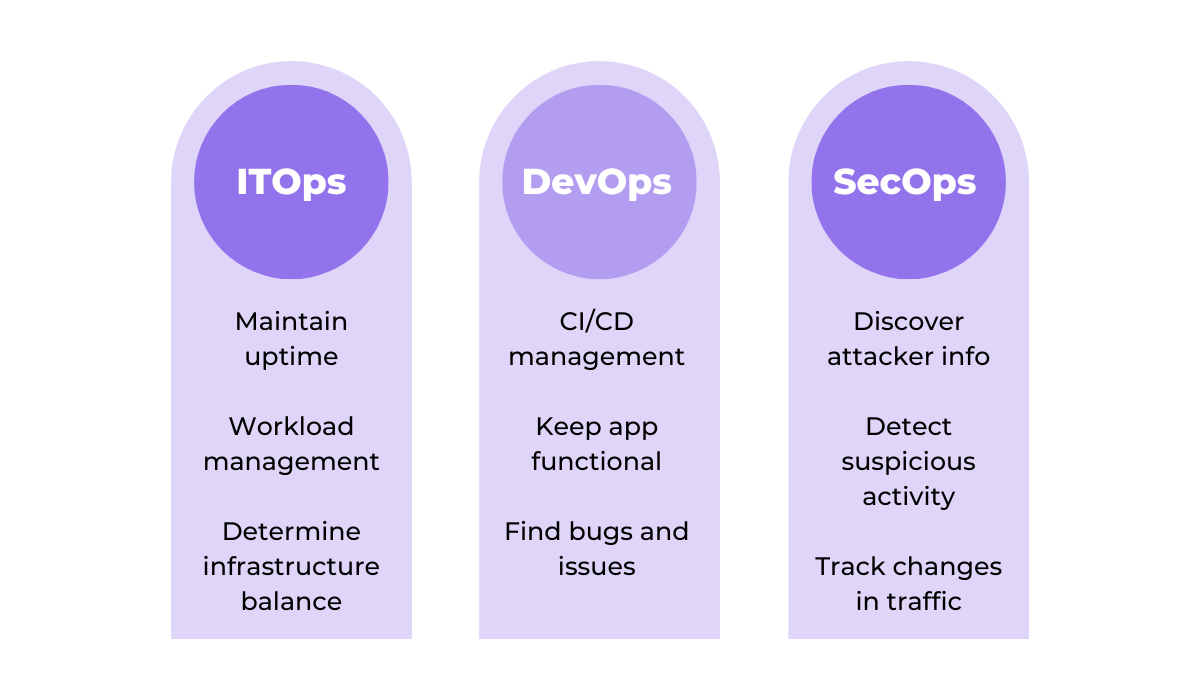
For example, logs that track user sign-in attempts might seem redundant to a DevOps team member but could offer crucial security insights for a SecOps professional.
ITOps and QA engineers will have other needs as well, and tailoring what logs are collected accordingly is essential for effective operations.
So, while it’s tempting to log everything, it’s more beneficial to log with purpose.
By ensuring each log has a clear intent, you can make your log management process more efficient and insightful.
Our fourth key practice for managing high-volume logs is structured logging.
Trust us, once your team adopts this approach, they’ll wonder how they ever managed without it.
Structured logging is about moving away from plain-text logs that are written for human eyes and embracing logs that are machine-readable.
Instead of collecting unstructured pieces of data, the structured approach involves logging in a specific and organized way, either in XML, JSON, or other formats.
Let’s illustrate what we mean with an example.
Imagine if you ran an e-commerce platform, and every time a customer made an order, the system logged the details for tracking shipments and troubleshooting issues.
An unstructured log would look something like the following image.
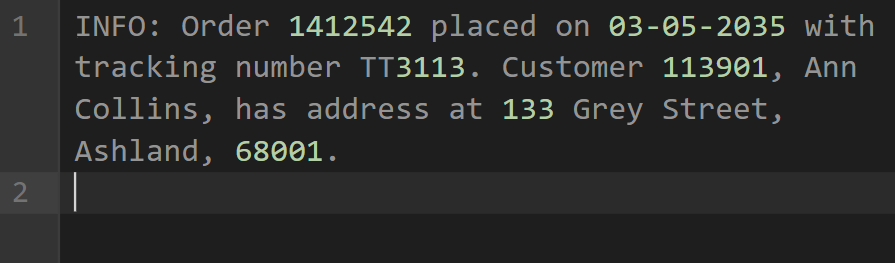
While we could figure out that the log is about order details and customer info, this message is not very friendly for machines.
Now, let’s see what this log would look like as a JSON-formatted log.
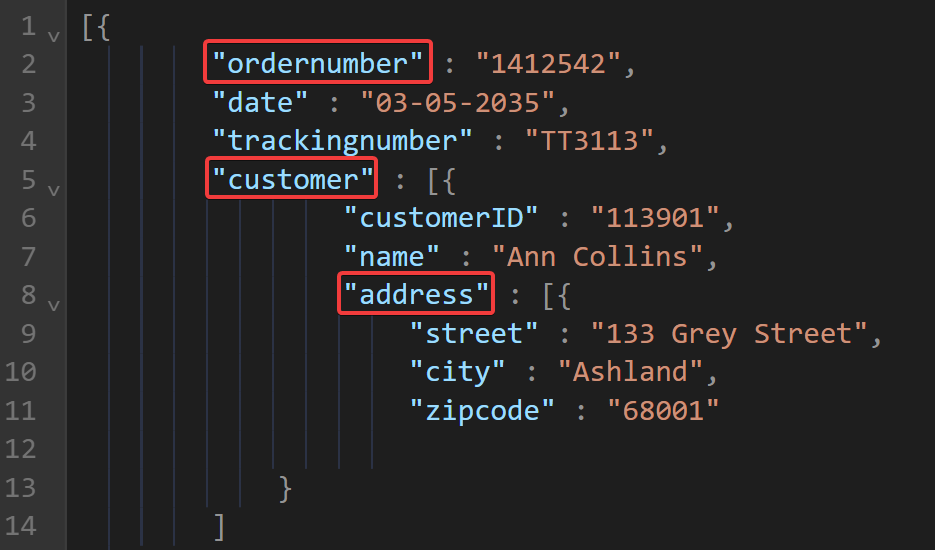
This version is not only more readable for us but is also structured in a way that machines love. Each piece of data has a clear label, making it easier to parse and analyze.
Why is machine readability so crucial for high-volume logs?
Well, when logs are structured, they can be easily parsed and analyzed, and they are flexible enough for new data to be entered easily.
Very handy for handling user feedback. CTOs, devs, testers – rejoice.
Let’s return to our e-commerce example.
Structured logs would allow you to query specific fields swiftly.
Want to see all orders from a particular customer or perhaps all orders shipped to a certain city on a specific date?
With structured logs, such queries become straightforward.
By ensuring your logs are both human-readable and machine-parsable, you set the stage for more efficient log management and more insightful data analysis.
Alright, so you’ve got your logs standardized, consistently formatted, purposefully created, and structured for easy parsing.
But the journey doesn’t end there.
Regular log analysis is the final piece of the puzzle to ensure you’re getting the most out of your app logging practices.
Log analysis, in a nutshell, is the process of examining log entries to extract meaningful insights, helping you identify patterns, anomalies, or potential issues that might otherwise go unnoticed.
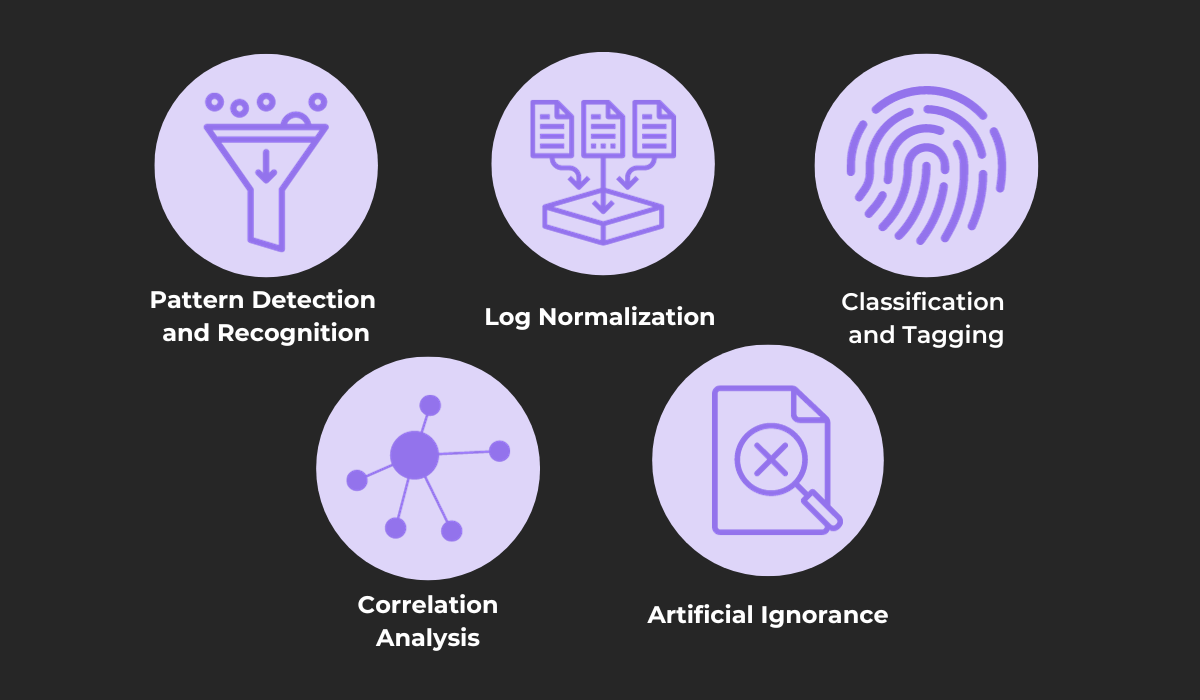
This practice uses a number of different techniques, some of which are shown in the next graphic.
Let’s focus on log normalization to illustrate how one of these techniques works.
Imagine you collected date logs from three different versions of an app, where each version had its own way of recording the date.
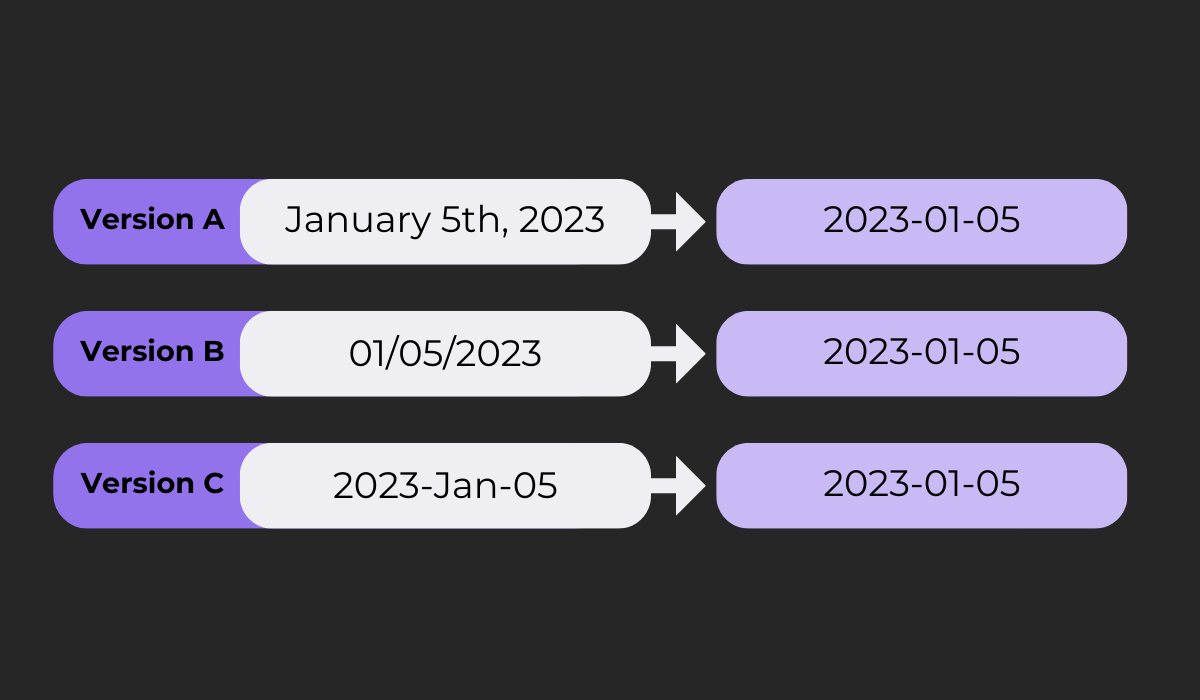
Log normalization is about taking these varied data formats and unifying them. In our example, all date formats are transformed into a consistent year-month-day format.
This practice ensures consistency and makes analysis more straightforward.
While diving deep into every technique is beyond our scope here, it’s worth noting that there are plenty of resources out there for those keen to explore further, like this Sematext article.
Also, don’t forget to check out the myriad of log analysis tools on the market that can help you utilize the various techniques we showed.

From premium solutions like Splunk and Sumo Logic to open-source gems like Graylog or GoAccess, there’s a tool for every need and budget that can drastically streamline your log analysis process.
In conclusion, while setting up and managing a large number of logs might seem like a chore, the insights these logs provide are invaluable.
Regular analysis is the key to unlocking these insights and ensuring your app’s continuous growth and stability.
And with that, we’ve finished delving into the complexities of managing high-volume app logs and highlighted five essential practices to keep things under control.
While there are many more tips you can implement, these five stand out as crucial practices for effective operations.
By leveraging these insights, teams can significantly optimize their log management processes, making it easier to diagnose issues, monitor an app’s performance, and gain the necessary information to make sure it’s running smoothly and efficiently.
Remember, when the essential data about your system is more organized, the overall efficiency and productivity of your operations will soar.
So, put some of what you’ve learned into practice and take care of the logging clutter.
From internal bug reporting to production and customer support, our all-in-one SDK gets you all the right clues to fix issues in your mobile app and website.
We love to think it makes CTOs life easier, QA tester’s reports better and dev’s coding faster. If you agree that user feedback is key – Shake is your door lock.
Read more about us here.

Add to app in minutes

Doesn’t affect app speed

GDPR & CCPA compliant

Unexpected things pop up
Just like bugs in your app or web 🐛 Fix them now with just one reporting tool.